Quick Introduction
DeepEval is an open-source evaluation framework for LLMs. DeepEval makes it extremely easy to build and iterate on LLM (applications) and was built with the following principles in mind:
- Easily "unit test" LLM outputs in a similar way to Pytest.
- Plug-and-use 14+ LLM-evaluated metrics, most with research backing.
- Custom metrics are simple to personalize and create.
- Define evaluation datasets in Python code.
- Real-time evaluations in production (available on Confident AI).
Setup A Python Environement
Go to the root directory of your project and create a virtual environement (if you don't already have one). In the CLI, run:
python3 -m venv venv
source venv/bin/activate
Installation
In your newly created virtual environement, run:
pip install -U deepeval
You can also keep track of all evaluation results by logging onto Confident AI, an all in one evaluation platform:
deepeval login
Contact us if you're dealing with sensitive data that has to reside in your private VPCs.
Create Your First Test Case
Run touch test_example.py to create a test file in your root directory. Open test_example.py and paste in your first test case:
import pytest
from deepeval import assert_test
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
def test_answer_relevancy():
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.5)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output of your LLM application
actual_output="We offer a 30-day full refund at no extra cost.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra cost."]
)
assert_test(test_case, [answer_relevancy_metric])
Run deepeval test run from the root directory of your project:
deepeval test run test_example.py
Congratulations! Your test case should have passed ✅ Let's breakdown what happened.
- The variable
inputmimics a user input, andactual_outputis a placeholder for what your application's supposed to output based on this input. - The variable
retrieval_contextcontains the retrieved context from your knowledge base, andAnswerRelevancyMetric(threshold=0.5)is an default metric provided bydeepevalfor you to evaluate your LLM output's relevancy based on the provided retrieval context. - All metric scores range from 0 - 1, which the
threshold=0.5threshold ultimately determines if your test have passed or not.
You'll need to set your OPENAI_API_KEY as an enviornment variable before running the AnswerRelevancyMetric, since the AnswerRelevancyMetric is an LLM-evaluated metric. To use ANY custom LLM of your choice, check out this part of the docs.
You can also save test results locally for each test run. Simply set the DEEPEVAL_RESULTS_FOLDER environement variable to your relative path of choice:
export DEEPEVAL_RESULTS_FOLDER="./data"
Create Your First Custom Metric
deepeval provides two types of custom metric to evaluate LLM outputs: metrics evaluated with LLMs and metrics evaluated without LLMs. Here is a brief overview of each:
LLM Evaluated Metrics
An LLM evaluated metric (aka. LLM-Evals), is one where evaluation is carried out by an LLM. deepeval offers more than a dozen LLM-Evals, one of which is G-Eval, a state-of-the-art framework to evaluate LLM outputs.
from deepeval import assert_test
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
...
def test_coherence():
coherence_metric = GEval(
name="Coherence",
criteria="Coherence - determine if the actual output is logical, has flow, and is easy to understand and follow.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
threshold=0.5
)
test_case = LLMTestCase(
input="What if these shoes don't fit? I want a full refund.",
# Replace this with the actual output from your LLM application
actual_output="If the shoes don't fit, the customer wants a full refund."
)
assert_test(test_case, [coherence_metric])
All of deepeval's default metrics are LLM-Evals, most of which are backed by associated research papers. To learn more, here is an article on everything you need to know about LLM evaluation metrics.
Non-LLM Evaluated Metrics
A non-LLM evaluated metric is a metric where evluation is not carried out by another LLM. Since all of deepeval's metrics are evaluated using LLMs, you'll have to created a custom metric instead by defining the measure and is_successful methods upon inheriting the base BaseMetric class.
from deepeval.metrics import BaseMetric
...
class LengthMetric(BaseMetric):
# This metric checks if the output length is greater than 10 characters
def __init__(self, max_length: int=10):
self.threshold = max_length
def measure(self, test_case: LLMTestCase):
self.success = len(test_case.actual_output) > self.threshold
if self.success:
score = 1
else:
score = 0
return score
def is_successful(self):
return self.success
@property
def __name__(self):
return "Length"
def test_length():
length_metric = LengthMetric(max_length=10)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output of your LLM application
actual_output="We offer a 30-day full refund at no extra cost."
)
assert_test(test_case, [length_metric])
Run deepeval test run from the root directory of your project again:
deepeval test run test_example.py
You should see both test_answer_relevancy and test_length passing.
Two things to note:
- Custom metrics requires a
threshsoldas a passing criteria. In the case of ourLengthMetric, the passing criteria was whether themax_lengthofactual_outputis greater than 10. - We removed
retrieval_contextintest_lengthsince it was irrelevant to evaluating output length. Howeverinputandactual_outputis always mandatory when creating anLLMTestCase.
You can also create a custom metric to combine several different metrics into one. For example. combining the AnswerRelevancyMetric and FaithfulnessMetric to test whether an LLM output is both relevant and faithful (ie. not hallucinating).
Combine Your Metrics
You might've noticed we have duplicated test cases for both test_answer_relevancy and test_length (ie. they have the same input and expected output). To avoid this redundancy, deepeval offers an easy way to apply as many metrics as you wish for a single test case.
...
def test_everything():
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
length_metric = LengthMetric(max_length=10)
coherence_metric = GEval(
name="Coherence",
criteria="Coherence - determine if the actual output is logical, has flow, and is easy to understand and follow.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
threshold=0.5
)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output of your LLM application
actual_output="We offer a 30-day full refund at no extra cost.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra cost."]
)
assert_test(test_case, [answer_relevancy_metric, coherence_metric, length_metric])
In this scenario, test_everything only passes if all metrics are passing. Run deepeval test run again to see the results:
deepeval test run test_example.py
Evaluate Your Evaluation Dataset
An evaluation dataset in deepeval is simply a collection of LLMTestCases and/or Goldens.
We're not going to dive into what a Golden is here, but it is an important concept if you're looking to generate LLM outputs at evlauation time. To learn more about Goldens, click here.
Using deepeval's Pytest integration, you can utilize the @pytest.mark.parametrize decorator to loop through and evaluate your evaluation dataset.
import pytest
from deepeval import assert_test
from deepeval.metrics import FaithfulnessMetric, AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
from deepeval.dataset import EvaluationDataset
first_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
second_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
# Initialize an evaluation dataset by supplying a list of test cases
dataset = EvaluationDataset(test_cases=[first_test_case, second_test_case])
# Loop through test cases using Pytest
@pytest.mark.parametrize(
"test_case",
dataset,
)
def test_customer_chatbot(test_case: LLMTestCase):
faithfulness_metric = FaithfulnessMetric(threshold=0.3)
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.5)
assert_test(test_case, [faithfulness_metric, answer_relevancy_metric])
You can also run test cases in parallel by using the optional -n flag followed by a number (that determines the number of processes that will be used) when executing deepeval test run:
deepeval test run test_dataset.py -n 2
Alternatively, you can evaluate entire datasets without going through the CLI (if you're in a notebook environment):
...
evaluate(test_cases, [faithfulness_metric, answer_relevancy_metric])
To learn more about the additional features an EvaluationDataset offers, visit the dataset section.
Using Confident AI
If you have reached this point, you've likely ran deepeval test run multiple times. To keep track of all future evaluation results created by deepeval, login to Confident AI by running the following command:
deepeval login
Confident AI is the platform powering deepeval, and allows anyone to:
- safeguard against breaking changes in CI/CD pipelines
- compare hyperparameters, such as model and prompt templates used
- centralize evaluation datasets on the cloud
- run real-time evaluations in production
Click here for the full documentation on using Confident AI with deepeval.
Follow the instructions displayed on the CLI to create an account, get your Confident API key, and paste it in the CLI.
Once you've pasted your Confident API key in the CLI, execute the previously created test file once more:
deepeval test run test_example.py
Analyze Test Runs
You should now see a link being returned upon test completion. Paste it in your browser to view results.
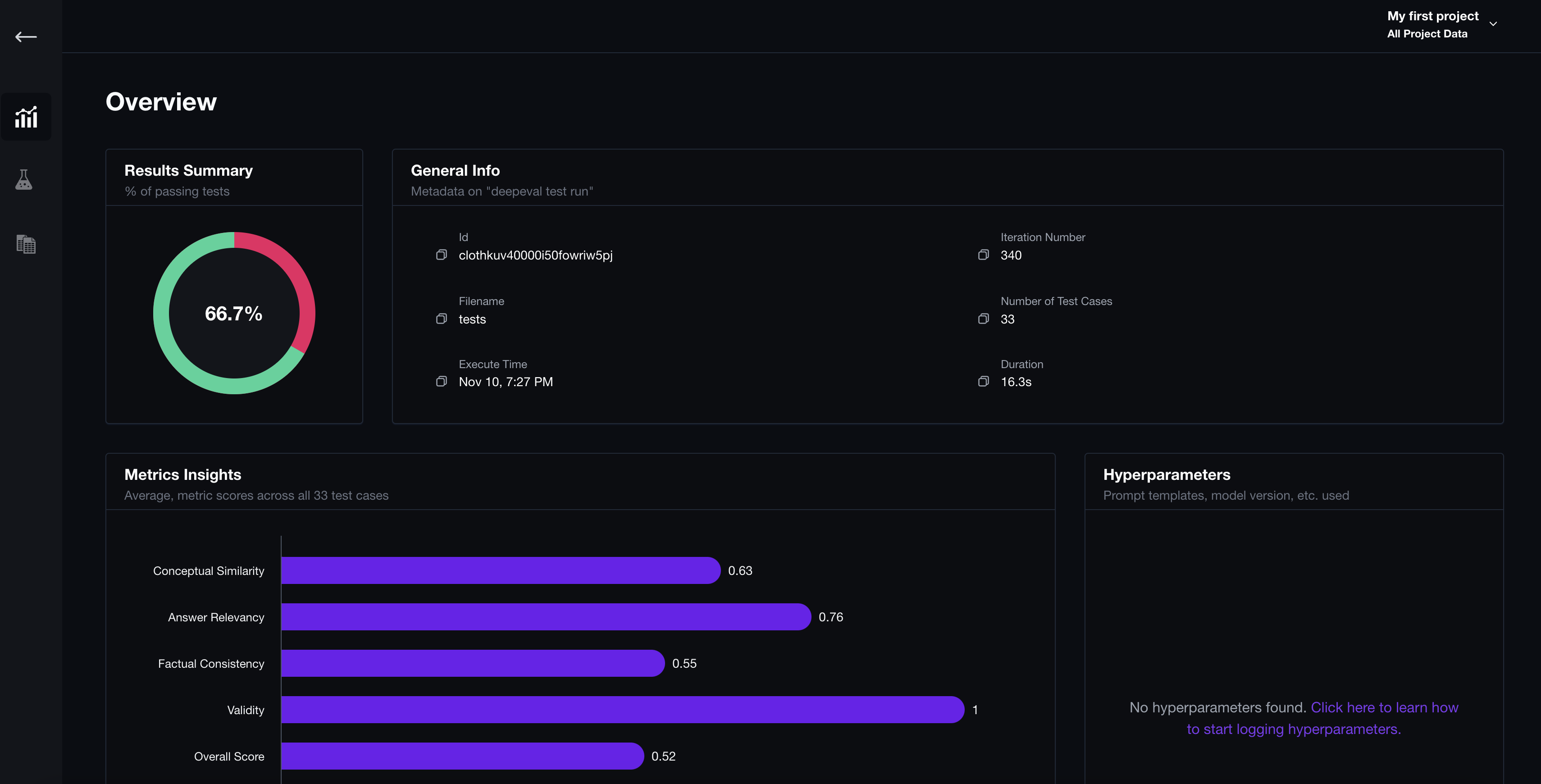
View Individual Test Cases
You can also view individual test cases for enhanced debugging:
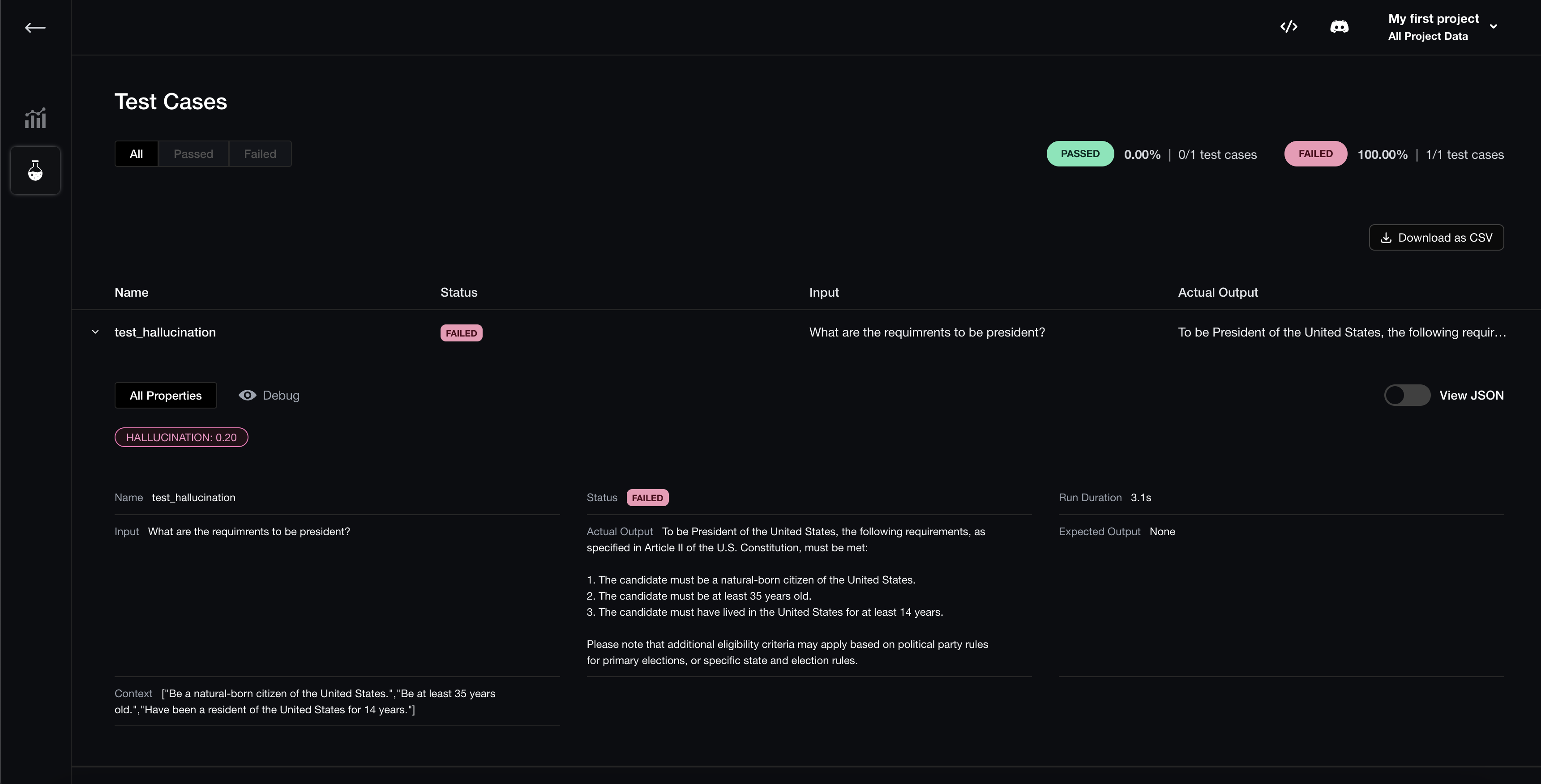
Compare Hyperparameters
To log hyperparameters (such as prompt templates used) for your LLM application, paste in the following code in test_example.py:
import deepeval
...
# Just an example of prompt_template
prompt_template = """You are a helpful assistant, answer the following question in a non-judgemental tone.
Question:
{question}
"""
# Although the values in this example are hardcoded,
# you should ideally pass in variables to keep things dynamic
@deepeval.log_hyperparameters(model="gpt-4", prompt_template=prompt_template)
def hyperparameters():
# Any additional hyperparameters you wish to keep track of
return {
"chunk_size": 500,
"temperature": 0
}
Execute deepeval test run test_example.py again to start comparing hyperparmeters for each test run.
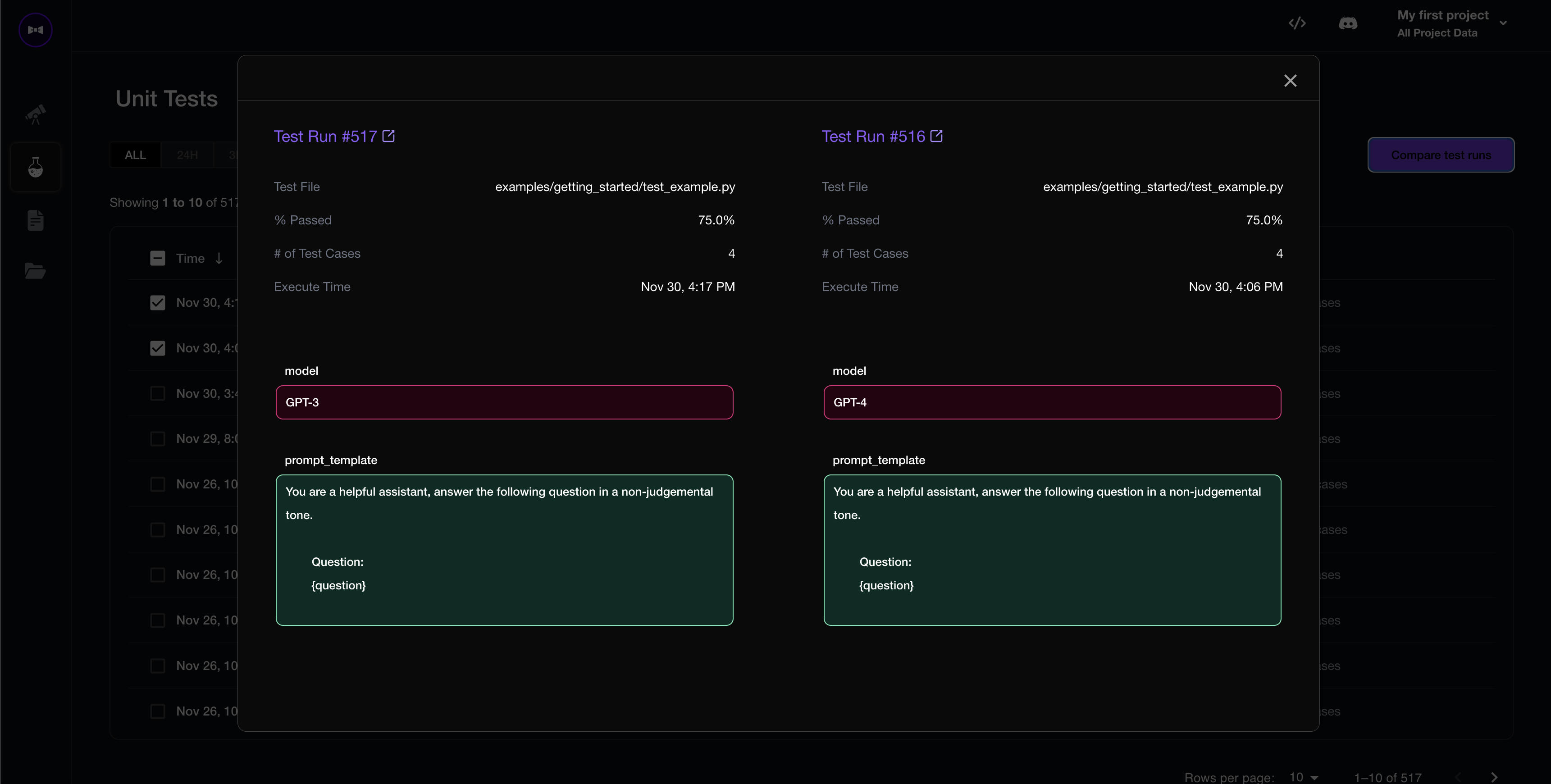
Full Example
You can find the full example here on our Github.